IberLEF eHealth-KD 2020: eHealth Knowledge Discovery
📃 The Overview paper and all Participant papers are available.
🗨️ Follow @EHealthKD on Twitter for up-to-date information.
Natural Language Processing (NLP) methods are increasingly being used to mine knowledge from unstructured health texts. Recent advances in health text processing techniques are encouraging researchers and health domain experts to go beyond just reading the information included in published texts (e.g. academic manuscripts, clinical reports, etc.) and structured questionnaires, to discover new knowledge by mining health contents. This has allowed other perspectives to surface that were not previously available.
Over the years, many eHealth challenges have attempted to identify, classify, extract, and link knowledge, such as Semevals, CLEF campaigns, and others.
The eHealth-KD 2020 proposes –as the previous editions eHealth-KD 2019 and eHealth-KD 2018– modeling the human language in a scenario in which Spanish electronic health documents could be machine-readable from a semantic point of view. With this task, we expect to encourage the development of software technologies to automatically extract a large variety of knowledge from eHealth documents written in the Spanish Language.
Even though this challenge is oriented to the health domain, the structure of the knowledge to be extracted is general-purpose. The semantic structure proposed models four types of information units. Each one represents a specific semantic interpretation, and they make use of thirteen semantic relations among them. The following sections provide a detailed presentation of each unit and relation type. An example is provided in the following picture.
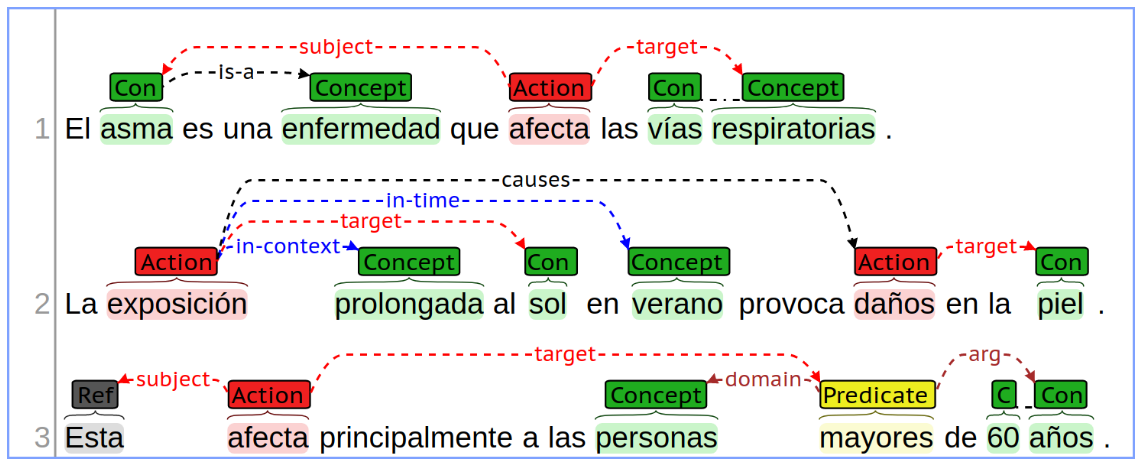
This challenge can be of interest to experts in the field of natural language processing, specifically for those working on automatic knowledge extraction and discovery. It is not a requirement to have expertise in health text processing for dealing with the eHealth-KD task, due to the general purpose of the semantic schema defined. Nevertheless, eHealth researchers could find interesting this challenge to evaluate their technologies that rely on health domain knowledge.
Novelties. This edition will involve an additional scenario in which an alternative domain (not health-related) will be evaluated, to experience with transfer learning techniques. Besides, COVID-19 related documents, i.e. news and documentation, will be available.
Official results
🏆 Special congratulations to Team Vicomtech for reaching the top results in this edition of the eHealth-KD challenge.
The official results for the eHealth-KD 2020 are ready 🎉!!
As explained, Scenario 1 is the main evaluation scenario. The results for Scenario 1 are summarized below.
The Overview paper summarizes the results in greater detail. Check all 📃 participants papers’ links in the table, and the 🎥 1-minute spotlight videos.
Scenario 1: Main evaluation
| Team | F1 | Precision | Recall | Paper | Video | |
|---|---|---|---|---|---|---|
| 🥇 | Vicomtech | 0.665564 | 0.679364 | 0.652315 | 📃 | 🎥 |
| 🥈 | Talp-UPC | 0.626679 | 0.626969 | 0.626389 | 📃 | 🎥 |
| 🥉 | UH-MAJA-KD | 0.625 | 0.634542 | 0.615741 | 📃 | 🎥 |
| IXA-NER-RE | 0.55748 | 0.58008 | 0.536574 | 📃 | 🎥 | |
| UH-MatCom | 0.556876 | 0.716157 | 0.455556 | 📃 | 🎥 | |
| SINAI | 0.42069 | 0.651456 | 0.310648 | 📃 | 🎥 | |
| HAPLAP | 0.395153 | 0.458435 | 0.347222 | 📃 | 🎥 | |
| ExSim | 0.245644 | 0.312589 | 0.202315 | 📃 | 🎥 |
The organizing committee of the eHealth-KD challenge wants to sincerely congratulate all participants for the high-quality submission and the impressive results, which have surpassed previous years.
See detailed results per team, scenario and run here.
Description of the Subtasks
To simplify the evaluation process, two subtasks are presented:
Submissions and evaluation
There are four evaluation scenarios:
- A main scenario covering both tasks
- An optional scenario evaluating subtask A
- An optional scenario evaluating subtask B
- An optional scenario in a completely different domain
The challenge will be graded in Codalab.
Resources
All the data will be made available to participants in due time. This includes training, development and test data, as well as evaluation scripts and sample submissions. More details are provided here.
Schedule
News
- 📃 The Overview paper and all Participant papers are available.
- 📢 Important information for participants in the Workshop.
- 🔗 Register now for IberLEF 2020. It’s free!
- 📢 Official results are now public !!.
- 📢 An official template for the working notes has been published.
- 👉 The deadline for the TEST phase has been extended to May 5th, 23:59 UTC.
- 👉 Testing files are ready. The testing phase in Codalab is officially open !!
- 👉 Due to the potential difficulties caused by COVID-19 to participants, we are delaying all dates starting with the test set release 2 weeks into the future.
- 👉 COVID19 related documents, i.e. news and documentation, will be played.
- 👉 An additional 100 sentences extracted from the Spanish version of Wikinews are available for cross-validation purposes, to evaluate transfer learning approaches (folder
data/development/transfer) (read more). - 👉 An additional 3000 automatically annotated sentences from Medline are available for further training. Note that these sentences have been manually revised and hence are not considered gold standard (read more).
| Date | Event | Link |
|---|---|---|
| 03 Feb 2020 | Training and development data ready | 📝 Sign Corpus License 🏃 Training and dev data |
| 30 Mar 2020 | Alternative scenario development data ready | 🏃 Alt dev data |
| 30 Mar 2020 | Ensemble dataset for augmenting training stage, ready | 🏃 Ensemble |
| 20 Apr 2020 |
Evaluation start Test data released |
⚗️ Test input files 🖥 Codalab submission |
| 05 May 2020 |
Evaluation end (due by 23:59 UTC) |
|
| 05 May 2020 |
Registration deadline (due by 23:59 UTC) |
|
| 08 May 2020 |
Results posted | 🏆 Official results |
| 22 May 2020 |
System description paper submissions (due by 23:59 UTC) |
📁 LaTeX template 📄 PDF guidelines |
| 07 Jun 2020 |
Paper reviews | |
| 12 Jun 2020 |
Author notifications | |
| 26 Jun 2020 |
Camera ready submissions | |
| 22 Sep 2020 | IberLEF Workshop (free registration) | 📆 Important info 🔑 Registration form 🔗IberLEF site |
Instructions for participation
The competition is managed and run in the Codalab Competitions platform. For participation, please register on the platform and follow the instructions detailed there. The following pages provide a detailed description of the problem to be solved and the evaluation. In Codalab you will find details about how to submit a solution, as well as all relevant links.
To download the relevant data, please visit here.
Publication instructions
The following instructions are subject to change to adapt to the official IberLEF 2020 requirements.
Send your paper to our Program Committee at chairs_eHealth-KD@googlegroups.com before (May 22th, 2020).
The Organization Committee of eHealth-KD encourages participants to submit a description paper of their systems. Submitted papers will be reviewed by a scientific committee, and only accepted papers will be published at CEUR. The proceedings of eHealth-KD will be jointly published with the proceedings of all tasks of IberLEF 2020. The submitted papers will be peer-reviewed by a Program Committee which is composed by all the participants and the Organization Committee.
The minimum length of the regular paper should be 5 (mandatory minimum) and up to 10 pages plus references formatted according to the following template:
Articles must be written in English. The document format can be Word or LaTeX, but the submission must be in PDF format. Please make sure to follow all the additional instructions provided in the template and respect the layout and formatting.
Depending on the final number of participants and the time allocated for the workshop, all or a selected group of papers will be presented and discussed in the Workshop session.
⚠️ If you prefer not to use LaTeX, the template is based on the Springer LLNCS templates for which Word examples exist. However, make sure to download the PDF guidelines since there are important details that your submission must comply with.
How to cite the challenge and the systems’ working-notes
In the following link you can find the preliminar bibtexts of the systems’ working-notes. In addition, to cite the eHealth-Kd challenge you can use the following preliminar bibtext:
@inproceedings{overview_ehealthkd2020,
author = {Piad{-}Morffis, Alejandro and
Guti{\'{e}}rrez, Yoan and
Ca{\~{n}}izares-Diaz, Hian and
Estevez{-}Velarde, Suilan and
Almeida{-}Cruz, Yudivi{\'{a}}n and
Mu{\~{n}}oz, Rafael and
Montoyo, Andr{\'{e}}s},
title = {Overview of the eHealth Knowledge Discovery Challenge at IberLEF 2020},
booktitle = ,
year = {2020},
}
Organization committee
| Name | Institution | |
|---|---|---|
| Yoan Gutiérrez Vázquez (contact person) | ygutierrez@dlsi.ua.es | University of Alicante, Spain |
| Suilan Estévez Velarde | sestevez@matcom.uh.cu | University of Havana, Cuba |
| Alejandro Piad Morffis | apiad@matcom.uh.cu | University of Havana, Cuba |
| Yudivián Almeida Cruz | yudy@matcom.uh.cu | University of Havana, Cuba |
| Andrés Montoyo Guijarro | montoyo@dlsi.ua.es | University of Alicante, Spain |
| Rafael Muñoz Guillena | rafael@dlsi.ua.es | University of Alicante, Spain |
Discussion group
A Google Group will be set up for this “Health Shared Task” where announcements will be made. Feel free to send your questions and feedback to ehealth-kd@googlegroups.com. General issues and feedback should be posted on our Issues Page in Github.
Follow @eHealthKD on Twitter for up-to-date news, comments and tips about the competition.
Funding
This research has been supported by a Carolina Foundation grant in agreement with University of Alicante and University of Havana. Moreover, it has also been partially funded by both aforementioned universities, IUII, Generalitat Valenciana, Spanish Government, Ministerio de Educación, Cultura y Deporte through the projects SIIA (PROMETEU/2018/089) and LIVINGLANG (RTI2018-094653-B-C22).
Scientific publications
Piad-Morffis, A., Gutiérrez, Y., & Muñoz, R. (2019). A corpus to support ehealth knowledge discovery technologies. Journal of biomedical informatics, 94, 103172.
Estevez-Velarde, S., Gutiérrez, Y., Montoyo, A., & Almeida-Cruz, Y. (2019, July). Automl strategy based on grammatical evolution: A case study about knowledge discovery from text. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 4356-4365).
Piad-Morffis, A., Guitérrez, Y., Estevez-Velarde, S., & Muñoz, R. (2019, June). A general-purpose annotation model for knowledge discovery: Case study in Spanish clinical text. In Proceedings of the 2nd Clinical Natural Language Processing Workshop (pp. 79-88).
Piad-Morffis, A., Gutiérrez, Y., Estévez-Velarde, S., Almeida-Cruz, Y., Montoyo, A., & Munoz, R. (2019). Analysis of eHealth knowledge discovery systems in the TASS 2018 Workshop. Procesamiento del Lenguaje Natural, 62, 13-20.
Estevez-Velarde, S., Gutiérrez, Y., Montoyo, A., & Almeida-Cruz, Y. (2019, October). Optimizing Natural Language Processing Pipelines: Opinion Mining Case Study. In Iberoamerican Congress on Pattern Recognition (pp. 163-173). Springer, Cham.
Piad-Morffis, A., Gutiérrez, Y., Consuegra-Ayala, J. P., Estevez-Velarde, S., Almeida-Cruz, Y., Munoz, R., & Montoyo, A. (2019). Overview of the ehealth knowledge discovery challenge at iberlef 2019. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2019). CEUR Workshop Proceedings, CEUR-WS. org.