IberLEF eHealth-KD 2019: eHealth Knowledge Discovery
Natural Language Processing (NLP) methods are increasingly being used to mine knowledge from unstructured health texts. Recent advances in health text processing techniques are encouraging researchers and health domain experts to go beyond just reading the information included in published texts (e.g. academic manuscripts, clinical reports, etc.) and structured questionnaires, to discover new knowledge by mining health contents. This has allowed other perspectives to surface that were not previously available.
Over the years many eHealth challenges have taken place, which have attempted to identify, classify, extract and link knowledge, such as Semevals, CLEF campaigns and others [1].
Inspired by previous NLP shared tasks like Semeval-2017 Task 10: ScienceIE and research lines like Teleologies [2],both not specifically focussed on the health area, and related previous TASS challenges, eHealth-KD 2019 proposes –as the previous edition eHealth-KD 2018– modeling the human language in a scenario in which Spanish electronic health documents could be machine readable from a semantic point of view. With this task, we expect to encourage the development of software technologies to automatically extract a large variety of knowledge from eHealth documents written in the Spanish Language.
Even though this challenge is oriented to the health domain, the structure of the knowledge to be extracted is general-purpose. The semantic structure proposed models four types of information units. Each one represents a specific semantic interpretation, and they make use of thirteen semantic relations among them. The following sections provide a detailed presentation of each unit and relation type. An example is provided in the following picture.
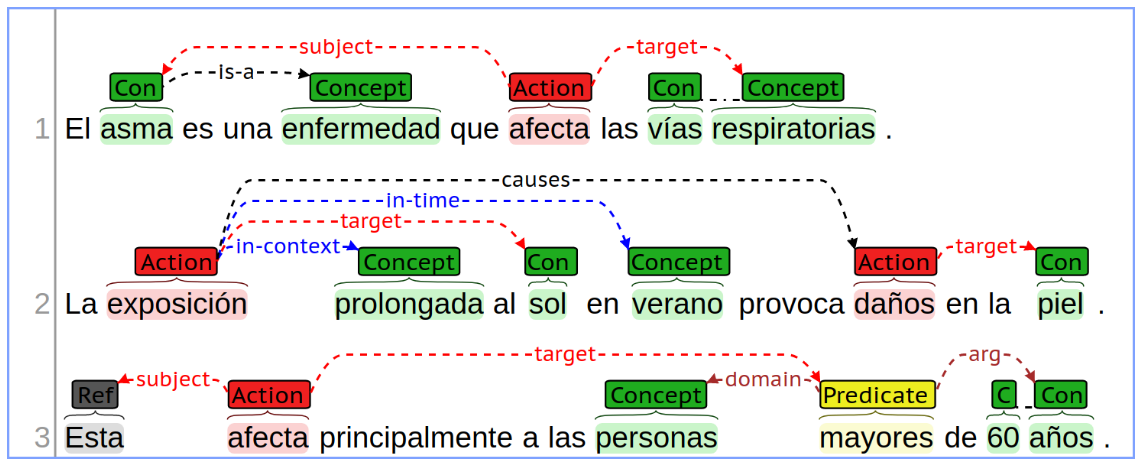
This challenge can be of interest for experts in the field of natural language processing, specifically for those working on automatic knowledge extraction and discovery. It is not a requirement to have expertise in health texts processing for dealing with the eHealth-KD task, due to the general purpose of the semantic schema defined. Nevertheless, eHealth researchers could find interesting this challenge to evaluate their technologies that rely on health domain knowledge.
Program details
The official Workshop Program details are already published. We hope to see you all at IberLEF 2019!
Official results of the eHealth-KD 2019 Challenge
We are pleased to inform that the official results for the 2019 challenge are already available! The following table summarizes the results for each scenario, sorted by F1 score.
Special congratulations to team TALP for achieving the highest F1 in all three scenarios!
We also want to congratulate and thank all participants for their efforts in building very complex and interesting solutions to the eHealth-KD problem. Several solutions rank very close to the top score in all scenarios, which is an evidence of the high quality of all submissions.
NOTE: Official team names and systems will be updated as they become available. Fill in this form to update your info: https://forms.gle/GyVF7SYKzDJuCHT27
Scenario 1
| No. | Team | F1 | Precision | Recall | System |
|---|---|---|---|---|---|
| 1 | TALP | 0.6394 | 0.6506 | 0.6286 | Joint-BERT-RCNN |
| 2 | coin_flipper (ncatala) | 0.6218 | 0.7454 | 0.5334 | Voting LSTMs |
| 3 | LASTUS-TALN (abravo) | 0.5816 | 0.7740 | 0.4658 | |
| 4 | NLP_UNED | 0.5473 | 0.6561 | 0.4695 | DeepNER+ARE |
| 5 | Hulat-TaskAB | 0.5413 | 0.7734 | 0.4163 | |
| 6 | UH-MAJA-KD | 0.5189 | 0.5644 | 0.4802 | MeDeepCal |
| 7 | lsi2_uned | 0.4934 | 0.7397 | 0.3702 | |
| 8 | IxaMed | 0.4869 | 0.6896 | 0.3763 | |
| 9 | baseline | 0.4309 | 0.5204 | 0.3677 | Baseline |
| 9 | Hulat-TaskA | 0.4309 | 0.5204 | 0.3677 | Baseline |
| 9 | VSP | 0.4289 | 0.4551 | 0.4056 | Baseline |
Scenario 2
| No. | Team | F1 | Precision | Recall | System |
|---|---|---|---|---|---|
| 1 | TALP | 0.8203 | 0.8073 | 0.8336 | Joint-BERT-RCNN |
| 2 | LASTUS-TALN (abravo) | 0.8167 | 0.7997 | 0.8344 | |
| 3 | UH-MAJA-KD | 0.8156 | 0.7999 | 0.8320 | MeDeepCal |
| 4 | Hulat-TaskA | 0.7903 | 0.7706 | 0.8111 | RNN-ICK |
| 5 | coin_flipper (ncatala) | 0.7873 | 0.7986 | 0.7763 | Voting LSTMs |
| 6 | Hulat-TaskAB | 0.7758 | 0.7500 | 0.8034 | |
| 7 | NLP_UNED | 0.7543 | 0.8069 | 0.7082 | DeepNER+ARE |
| 8 | lsi2_uned | 0.7315 | 0.7817 | 0.6873 | |
| 9 | IxaMed | 0.6825 | 0.6567 | 0.7105 | |
| 10 | baseline | 0.5466 | 0.5129 | 0.5851 | Baseline |
| 10 | VSP | 0.5466 | 0.5129 | 0.5851 | Baseline |
Scenario 3
| No. | Team | F1 | Precision | Recall | System |
|---|---|---|---|---|---|
| 1 | TALP | 0.6269 | 0.6667 | 0.5915 | Joint-BERT-RCNN |
| 2 | NLP_UNED | 0.5337 | 0.6235 | 0.4665 | DeepNER+ARE |
| 3 | VSP | 0.4933 | 0.5892 | 0.4243 | BiLSTM + Pos. |
| 4 | coin_flipper (ncatala) | 0.4931 | 0.7133 | 0.3768 | Voting LSTMs |
| 5 | IxaMed | 0.4356 | 0.5195 | 0.3750 | |
| 6 | UH-MAJA-KD | 0.4336 | 0.4306 | 0.4366 | MeDeepCal |
| 7 | LASTUS-TALN (abravo) | 0.2298 | 0.1705 | 0.3521 | |
| 8 | baseline | 0.1231 | 0.4878 | 0.0704 | Baseline |
| 8 | Hulat-TaskAB | 0.1231 | 0.4878 | 0.0704 | Baseline |
| 8 | Hulat-TaskA | 0.1231 | 0.4878 | 0.0704 | Baseline |
| 8 | lsi2_uned | 0.1231 | 0.4878 | 0.0704 | Baseline |
Detailed submission statistics are available in this spreadsheet.
Description of the Subtasks
To simplify the evaluation process, two subtasks are presented:
Submissions and evaluation
The challenge will be graded in Codalab.
There are three evaluation scenarios:
- A main scenario covering both tasks
- An optional scenario evaluating subtask A
- An optional scenario evaluation subtask B
Resources
All the data will be made available to participants in due time. This includes training, development and test data, as well as evaluation scripts and sample submissions. More details are provided here.
Schedule
| Date | Event | Link |
|---|---|---|
| 11 Feb 2019 | Trial data ready | Trial data in Github |
| 01 Apr 2019 | Training and development data ready | Training and dev data |
| 29 Apr 2019 | Registration deadline (due by 23:59 GMT -12:00) |
Registration form Codalab form |
| 30 Apr 2019 | Evaluation start Test data released |
Codalab form |
| 14 May 2019 | Evaluation end (due by 23:59 UTC) |
|
| 20 May 2019 | Results posted | Official results, Codalab results |
| 06 Jun 2019 | System description paper submissions (due by 23:59 UTC) |
Publication instructions |
| 14 Jun 2019 | Paper reviews | |
| 17 Jun 2019 | Author notifications | |
| 24 Jun 2019 | Camera ready submissions | |
| 24 Sep 2019 | eHealth-KD Workshop @ IberLEF 2019 | Program details |
Instructions for participation
The competition is managed and run in the Codalab Competitions platform. For participation, please register on the platform and follow the instructions detailed there. The following pages provide a detailed description of the problem to be solved and the evaluation. In Codalab you will find details about how to submit a solution, as well as all relevant links.
Click here to enter the competition.
To download the relevant data, please visit here.
Publication instructions
The following instructions are subject to change to adapt to the official IberLEF 2019 requirements.
Send your paper to our Program Comitee at chairs_eHealth-KD@googlegroups.com before June 3rd, 2019.
The Organization Committee of eHealth-KD encourages participants to submit a description paper of their systems. Submitted papers will be reviewed by a scientific committee, and only accepted papers will be published at CEUR. The proceedings of eHealth-KD will be jointly published with the proceedings of all tasks of IberLEF 2019. The submitted papers will be peer-reviewed by a Program Commitee which is composed by all the participants and the Organization Commitee.
The manuscripts must satisfy the following rules:
The minimum length of the regular paper should be 5 (mandatory minimum) and up to 10 pages plus references formatted according to the Conference Proceedings Springer template. The style that appears in the template by default must be used.
- Articles can be written in English. The title, abstract and keywords must be written in English.
- The document format must be Word or Latex, but the submission must be in PDF format.
- Instead of describing the task and/or the corpus, you should focus on the description of your experiments and the analysis of your results, and include a citation to the Overview paper. Indications for this citation will be provided in due time.
- Depending on the final number of participants and the time allocated for the workshop, all or a selected group of papers will be presented and discussed in the Workshop session.
Publication list
Click here to access to the system description papers.
How to reference the overview description paper?
For referencing the overview description paper the following bibtex is provided [download]:
@inproceedings{DBLP:conf/sepln/Piad-MorffisGCE19,
author = {Alejandro Piad{-}Morffis and
Yoan Guti{\'{e}}rrez and
Juan Pablo Consuegra{-}Ayala and
Suilan Estevez{-}Velarde and
Yudivi{\'{a}}n Almeida{-}Cruz and
Rafael Mu{\~{n}}oz and
Andr{\'{e}}s Montoyo},
title = {Overview of the eHealth Knowledge Discovery Challenge at IberLEF 2019},
booktitle = {Proceedings of the Iberian Languages Evaluation Forum co-located with
35th Conference of the Spanish Society for Natural Language Processing,
IberLEF@SEPLN 2019, Bilbao, Spain, September 24th, 2019.},
pages = {1--16},
year = {2019},
crossref = {DBLP:conf/sepln/2019iberlef},
url = {http://ceur-ws.org/Vol-2421/eHealth-KD\_overview.pdf},
timestamp = {Fri, 30 Aug 2019 13:15:06 +0200},
biburl = {https://dblp.org/rec/bib/conf/sepln/Piad-MorffisGCE19},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Organization committee
| Name | Institution | |
|---|---|---|
| Yoan Gutiérrez Vázquez* | ygutierrez@dlsi.ua.es | University of Alicante, Spain |
| Suilan Estévez Velarde | sestevez@matcom.uh.cu | University of Havana, Cuba |
| Alejandro Piad Morffis | apiad@matcom.uh.cu | University of Havana, Cuba |
| Yudivián Almeida Cruz | yudy@matcom.uh.cu | University of Havana, Cuba |
| Andrés Montoyo Guijarro | montoyo@dlsi.ua.es | University of Alicante, Spain |
| Rafael Muñoz Guillena | rafael@dlsi.ua.es | University of Alicante, Spain |
(*) Contact person
Discussion group
A Google Group will be set up for this “eHealth Shared Task” where announcements will be made. Feel free to send your questions and feedback to ehealth-kd@googlegroups.com. General issues and feedback should be posted on our Issues Page in Github.
Follow @eHealthKD on Twitter for up-to-date news, comments and tips about the competition.
Funding
This research has been supported by a Carolina Foundation grant in agreement with University of Alicante and University of Havana, sponsoring to Suilan Estévez Velarde. Moreover, it has also been partially funded by both aforementioned universities, Generalitat Valenciana, Spanish Government, Ministerio de Educación, Cultura y Deporte through the project PROMETEU/2018/089.
Scientific publications
Piad-Morffis, A., Gutiérrez, Y., & Muñoz, R. (2019). A corpus to support ehealth knowledge discovery technologies. Journal of biomedical informatics, 94, 103172.
Estevez-Velarde, S., Gutiérrez, Y., Montoyo, A., & Almeida-Cruz, Y. (2019, July). Automl strategy based on grammatical evolution: A case study about knowledge discovery from text. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 4356-4365).
Piad-Morffis, A., Guitérrez, Y., Estevez-Velarde, S., & Muñoz, R. (2019, June). A general-purpose annotation model for knowledge discovery: Case study in Spanish clinical text. In Proceedings of the 2nd Clinical Natural Language Processing Workshop (pp. 79-88).
Piad-Morffis, A., Gutiérrez, Y., Estévez-Velarde, S., Almeida-Cruz, Y., Montoyo, A., & Munoz, R. (2019). Analysis of eHealth knowledge discovery systems in the TASS 2018 Workshop. Procesamiento del Lenguaje Natural, 62, 13-20.
Estevez-Velarde, S., Gutiérrez, Y., Montoyo, A., & Almeida-Cruz, Y. (2019, October). Optimizing Natural Language Processing Pipelines: Opinion Mining Case Study. In Iberoamerican Congress on Pattern Recognition (pp. 163-173). Springer, Cham.
Piad-Morffis, A., Gutiérrez, Y., Consuegra-Ayala, J. P., Estevez-Velarde, S., Almeida-Cruz, Y., Munoz, R., & Montoyo, A. (2019). Overview of the ehealth knowledge discovery challenge at iberlef 2019. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2019). CEUR Workshop Proceedings, CEUR-WS. org.
References
[1] Gonzalez-Hernandez, G. and Sarker, A. and O’Connor, K. and Savova, G. Capturing the Patient’s Perspective: a Review of Advances in Natural Language Processing of Health-Related Text. Yearbook of medical informatics; 26(01), p 214–227. 2017
[2] Giunchiglia, F., & Fumagalli, M. (2017, November). Teleologies: Objects, Actions and Functions. In International Conference on Conceptual Modeling (pp. 520-534). Springer, Cham.